Chatgpt Maker怀疑中国的污垢廉价DeepSeek AI模型是使用OpenAI数据建造的,而具有讽刺意味
Openai怀疑中国人工智能模型比西方同行的DeepSeek可能已经使用OpenAI的数据进行了培训。这种启示,加上DeepSeek的迅速流行,引发了主要AI公司的市场经济下滑。 NVIDIA是GPU技术对AI模型开发至关重要的关键参与者,经历了其有史以来最大的单日股票损失,损失了近6000亿美元的市场价值。微软,Meta,Alphabet和Dell等其他公司也显着下降。
DeepSeek的R1车型被作为Chatgpt的一种具有成本效益的替代品,据报道,使用开源DeepSeek-V3接受了600万美元的培训。尽管辩论成本索赔,但该事件引起了人们对美国科技巨头投资数十亿美元投资的数十亿美元的担忧,从而引起了投资者的担忧。 DeepSeek在美国应用程序下载的成功进一步强调了这一问题。
Openai和Microsoft正在调查DeepSeek是否采用一种称为“蒸馏”的技术违反了OpenAI的服务条款 - 从较大的模型中提取数据来培训较小的数据。 Openai证实了其对中国和其他公司复制美国AI模型的尝试的认识,并表示其致力于保护其知识产权的承诺,包括与美国政府的合作。
特朗普总统的AI顾问戴维·萨克斯(David Sacks)支持以下说法:DeepSeek使用Openai的型号,预计领导AI公司的对策以防止类似的行动。
考虑到自己过去的争议,这种情况突出了Openai立场的讽刺意味。 Openai此前曾认为,如果没有使用受版权保护的材料,就不可能创建像Chatgpt这样的AI模型,这是他们向英国上议院提交的立场。纽约时报和17位指控侵犯版权的作者的诉讼挑战了这种理由。 Openai坚持认为其培训实践构成“合理使用”。正在进行的法律斗争和DeepSeek事件强调了围绕AI发展和版权的复杂而不断发展的法律景观。














-
1

2025年Nintendo Switch上的每个神奇宝贝游戏
Feb 25,2025
-
2

明星山谷:一个完整的附魔和武器锻造指南
Mar 17,2025
-
3
![动漫先锋层列表 - 每个游戏码的最佳单元[UPDATE 3.0]](https://images.gzztb.com/uploads/35/17376012656791b0f12fa1c.jpg)
动漫先锋层列表 - 每个游戏码的最佳单元[UPDATE 3.0]
Feb 27,2025
-
4

Roblox:卡车运输帝国代码(2025年1月)
Mar 05,2025
-
5

热门 MMORPG Ragnarok Online 的休闲格斗衍生作品《波利冲刺》现已推出
Dec 30,2024
-
6

ragnarok X:下一代 - 完整的结界指南
May 25,2025
-
7

如何阅读《黑豹》传说:漫威竞争对手的国王之血
Mar 01,2025
-
8

NVIDIA RTX 5090规格泄漏:谣言确认?
Mar 14,2025
-
9
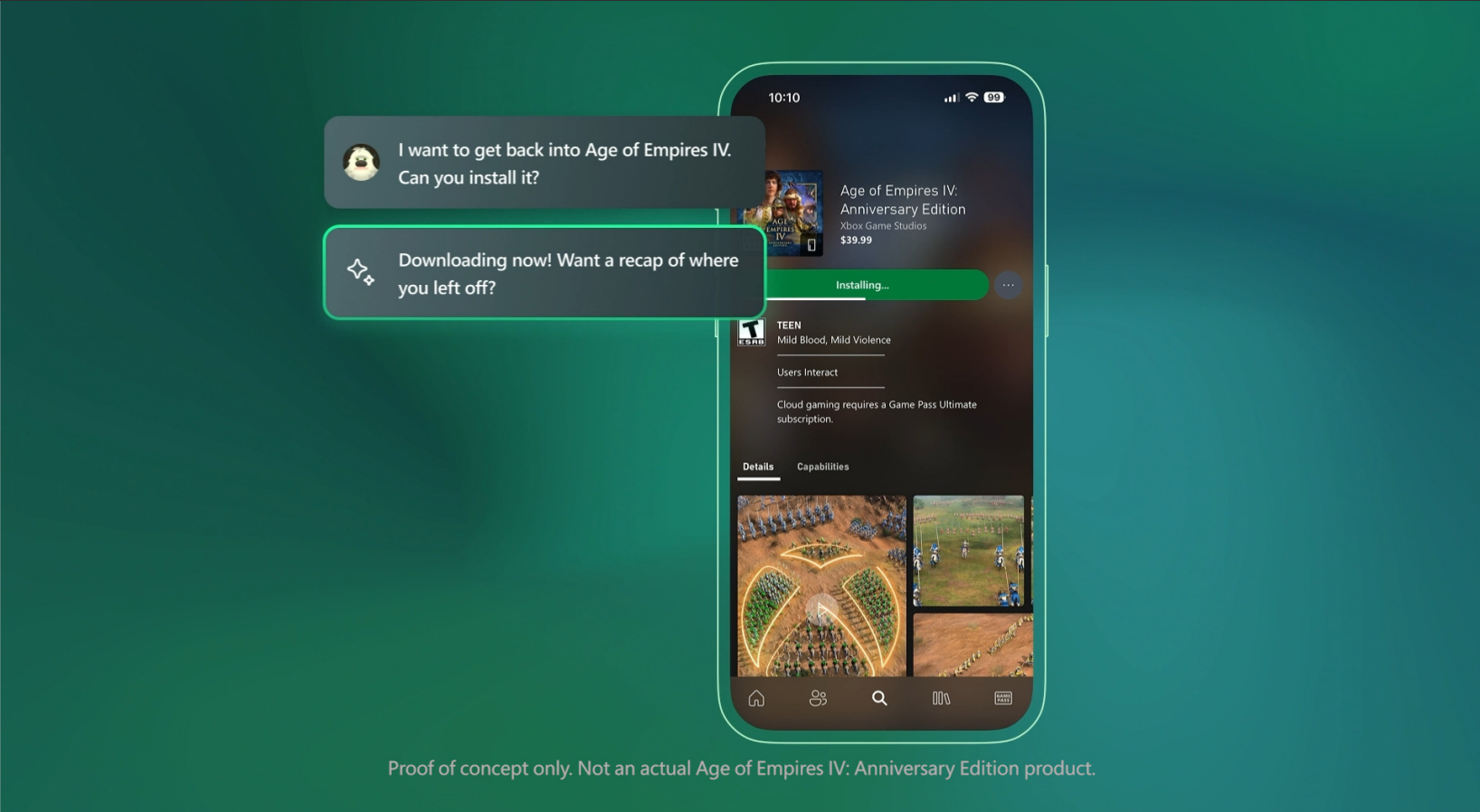
Microsoft将Copilot AI集成到Xbox应用程序和游戏中
May 21,2025
-
10

迈凯伦回归 배틀그라운드 合作
Aug 27,2024


