Chatgpt Maker懷疑中國的汙垢廉價DeepSeek AI模型是使用OpenAI數據建造的,而具有諷刺意味
Openai懷疑中國人工智能模型比西方同行的DeepSeek可能已經使用OpenAI的數據進行了培訓。這種啟示,加上DeepSeek的迅速流行,引發了主要AI公司的市場經濟下滑。 NVIDIA是GPU技術對AI模型開發至關重要的關鍵參與者,經曆了其有史以來最大的單日股票損失,損失了近6000億美元的市場價值。微軟,Meta,Alphabet和Dell等其他公司也顯著下降。
DeepSeek的R1車型被作為Chatgpt的一種具有成本效益的替代品,據報道,使用開源DeepSeek-V3接受了600萬美元的培訓。盡管辯論成本索賠,但該事件引起了人們對美國科技巨頭投資數十億美元投資的數十億美元的擔憂,從而引起了投資者的擔憂。 DeepSeek在美國應用程序下載的成功進一步強調了這一問題。
Openai和Microsoft正在調查DeepSeek是否采用一種稱為“蒸餾”的技術違反了OpenAI的服務條款 - 從較大的模型中提取數據來培訓較小的數據。 Openai證實了其對中國和其他公司複製美國AI模型的嚐試的認識,並表示其致力於保護其知識產權的承諾,包括與美國政府的合作。
特朗普總統的AI顧問戴維·薩克斯(David Sacks)支持以下說法:DeepSeek使用Openai的型號,預計領導AI公司的對策以防止類似的行動。
考慮到自己過去的爭議,這種情況突出了Openai立場的諷刺意味。 Openai此前曾認為,如果沒有使用受版權保護的材料,就不可能創建像Chatgpt這樣的AI模型,這是他們向英國上議院提交的立場。紐約時報和17位指控侵犯版權的作者的訴訟挑戰了這種理由。 Openai堅持認為其培訓實踐構成“合理使用”。正在進行的法律鬥爭和DeepSeek事件強調了圍繞AI發展和版權的複雜而不斷發展的法律景觀。














-
1

2025年Nintendo Switch上的每個神奇寶貝遊戲
Feb 25,2025
-
2

明星山谷:一個完整的附魔和武器鍛造指南
Mar 17,2025
-
3

Roblox:卡車運輸帝國代碼(2025年1月)
Mar 05,2025
-
4
![動漫先鋒層列表 - 每個遊戲碼的最佳單元[UPDATE 3.0]](https://images.gzztb.com/uploads/35/17376012656791b0f12fa1c.jpg)
動漫先鋒層列表 - 每個遊戲碼的最佳單元[UPDATE 3.0]
Feb 27,2025
-
5

熱門 MMORPG Ragnarok Online 的休閑格鬥衍生作品《波利衝刺》現已推出
Dec 30,2024
-
6

ragnarok X:下一代 - 完整的結界指南
May 25,2025
-
7

如何閱讀《黑豹》傳說:漫威競爭對手的國王之血
Mar 01,2025
-
8

NVIDIA RTX 5090規格洩漏:謠言確認?
Mar 14,2025
-
9
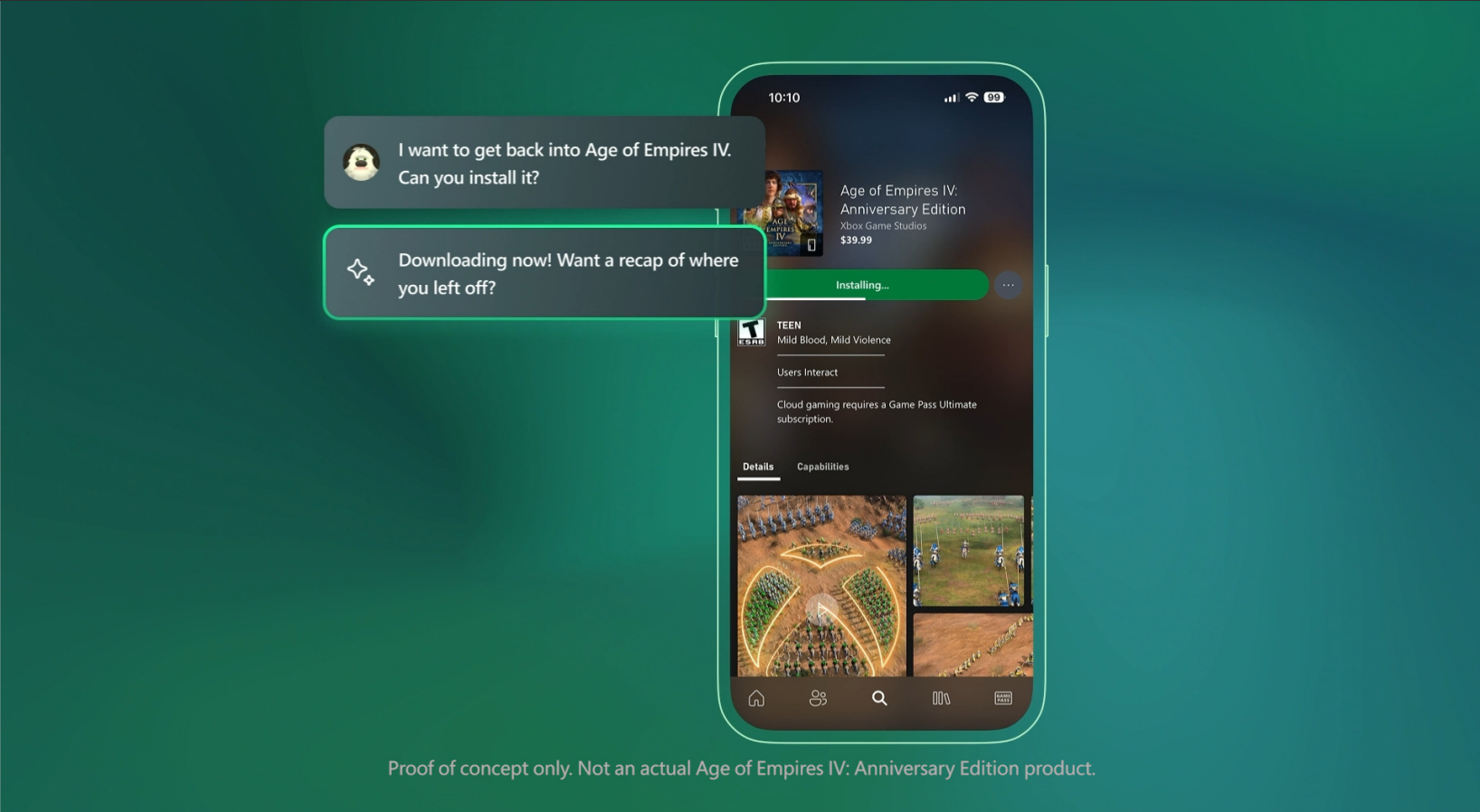
Microsoft將Copilot AI集成到Xbox應用程序和遊戲中
May 21,2025
-
10

麥克拉倫回歸 배틀그라운드 合作
Aug 27,2024


